Gender Entity Analysis Using NLTK
Russian vs French Monarchies Comparison



Importing
import nltk
nltk.download('averaged_perceptron_tagger')
nltk.download("names")
nltk.download("genesis")
nltk.download("inaugural")
nltk.download("nps_chat")
nltk.download("webtext")
nltk.download("treebank")
nltk.download('gutenberg')
nltk.download('punkt')
Defining our functions
def is_name(word):
return True if word in names else False
def is_female_name(word):
return True if word in female_names else False
def get_web_text(url1):
from bs4 import BeautifulSoup
from urllib import request
html1 = request.urlopen(url1).read().decode('utf8')
the_text= BeautifulSoup(html1, 'html.parser').get_text()
return the_text
def top_names(number,text):
txt_names=[name for name in filter(is_name,text)]
names_freq=nltk.FreqDist(txt_names)
top_names={}
for name,count in names_freq.most_common(number):
top_names[name]=count
return top_names
Scraping from the web with BeautifulSoup
Both English Values from Wikipedia:
1st
2nd
Analyzing with ‘names’ corpus
names=nltk.corpus.names.words()
female_names=nltk.corpus.names.words('female.txt')
male_names = nltk.corpus.names.words('male.txt')
Getting our outputs detecting & sorting
def analyze_text_names(url1):
web_text=nltk.word_tokenize(get_web_text(url1))
all_names=[name for name in filter(is_name,web_text)]
all_names_dict=sorted(set(all_names))
female_names_dict=[name for name in filter(is_female_name,all_names_dict)]
print("\r\n url: " + url1)
print("\r\n percentage of female names: " + "{:.1%}".format(len(female_names_dict) / len(all_names_dict)))
print("\r\n all names: ("+ str(len(all_names_dict))+")\r\n" + str(all_names_dict))
print("\r\n female names: ("+str(len(female_names_dict)) +") \r\n" + str(female_names_dict))
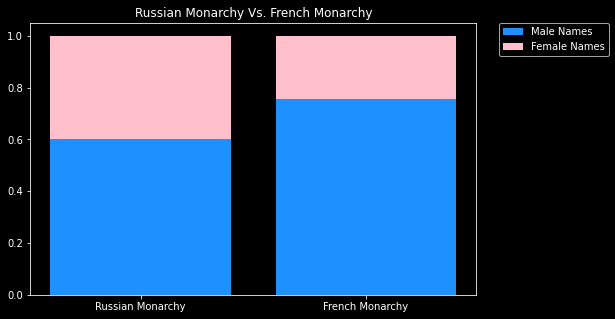
Femenine names vs. Masculine names in each wiki value


Displaying our outputs
#__________________________________________________
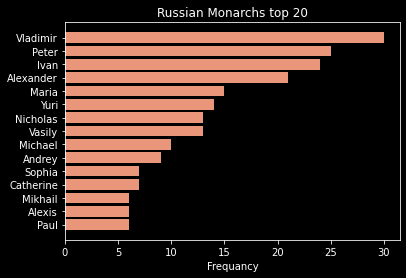
analyze_text_names("https://en.wikipedia.org/wiki/List_of_Russian_monarchs")
url: https://en.wikipedia.org/wiki/List_of_Russian_monarchs
all names: (60)
['Alexander', 'Alexandra', 'Alexis', 'Alta', 'Anastasia', 'Andrei', 'Andrew', 'Andrey', 'Anna', 'Anne', 'April', 'August', 'Boris', 'Canada', 'Catherine', 'Christina', 'Cookie', 'Curtis', 'Cyril', 'Daniel', 'Dimitri', 'Duke', 'Elena', 'Elizabeth', 'France', 'George', 'Glenn', 'Harvard', 'Igor', 'Ivan', 'June', 'Karl', 'King', 'Konstantin', 'Lucia', 'Maria', 'May', 'Maya', 'Michael', 'Mikhail', 'Natalia', 'Natalya', 'Nicholas', 'Oleg', 'Olga', 'Paul', 'Peter', 'Prince', 'Royal', 'Saul', 'See', 'Simeon', 'Simon', 'Sophia', 'Vasili', 'Vasily', 'Vincent', 'Vladimir', 'Xenia', 'Yuri']
female names: (28)
['Alexandra', 'Alexis', 'Alta', 'Anastasia', 'Andrei', 'Anna', 'Anne', 'April', 'Canada', 'Catherine', 'Christina', 'Cookie', 'Daniel', 'Elena', 'Elizabeth', 'France', 'George', 'Glenn', 'June', 'Lucia', 'Maria', 'May', 'Maya', 'Natalia', 'Natalya', 'Olga', 'Sophia', 'Xenia']
percentage of female names: 46.7 %
#__________________________________________________
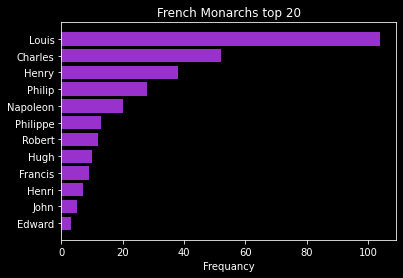
analyze_text_names("https://en.wikipedia.org/wiki/List_of_French_monarchs")
url: https://en.wikipedia.org/wiki/List_of_French_monarchs
all names: (53)
['Adrien', 'Antoine', 'April', 'August', 'Auguste', 'Augustus', 'Brewer', 'Catherine', 'Charles', 'Clovis', 'Cookie', 'David', 'Duke', 'Edward', 'France', 'Francis', 'French', 'George', 'Gita', 'Henri', 'Henry', 'Hercule', 'Hugh', 'Isabella', 'Jean', 'Joan', 'John', 'June', 'King', 'Lion', 'Louis', 'Magnus', 'Mary', 'May', 'Michael', 'Napoleon', 'Pascal', 'Philip', 'Philippe', 'Prince', 'Raoul', 'Rex', 'Richard', 'Robert', 'Rudolph', 'See', 'Son', 'Sterling', 'Temple', 'Walter', 'Webster', 'West', 'Whitney']
female names: (18)
['Adrien', 'April', 'Auguste', 'Catherine', 'Clovis', 'Cookie', 'France', 'Francis', 'George', 'Gita', 'Isabella', 'Jean', 'Joan', 'June', 'Mary', 'May', 'Philippe', 'Whitney']
percentage of female names: 34.0 %
Visualizing the results
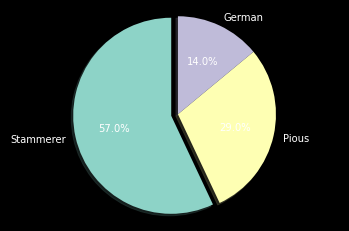
Most common names in French Monarchy:
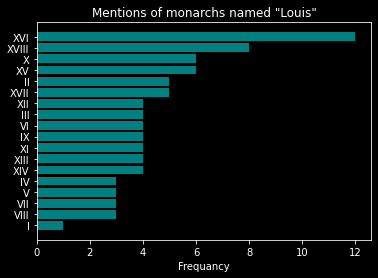
Most common names in Russian Monarchy:

Proportion of Femenine/ Masculine Entities Mentioned in values compared: